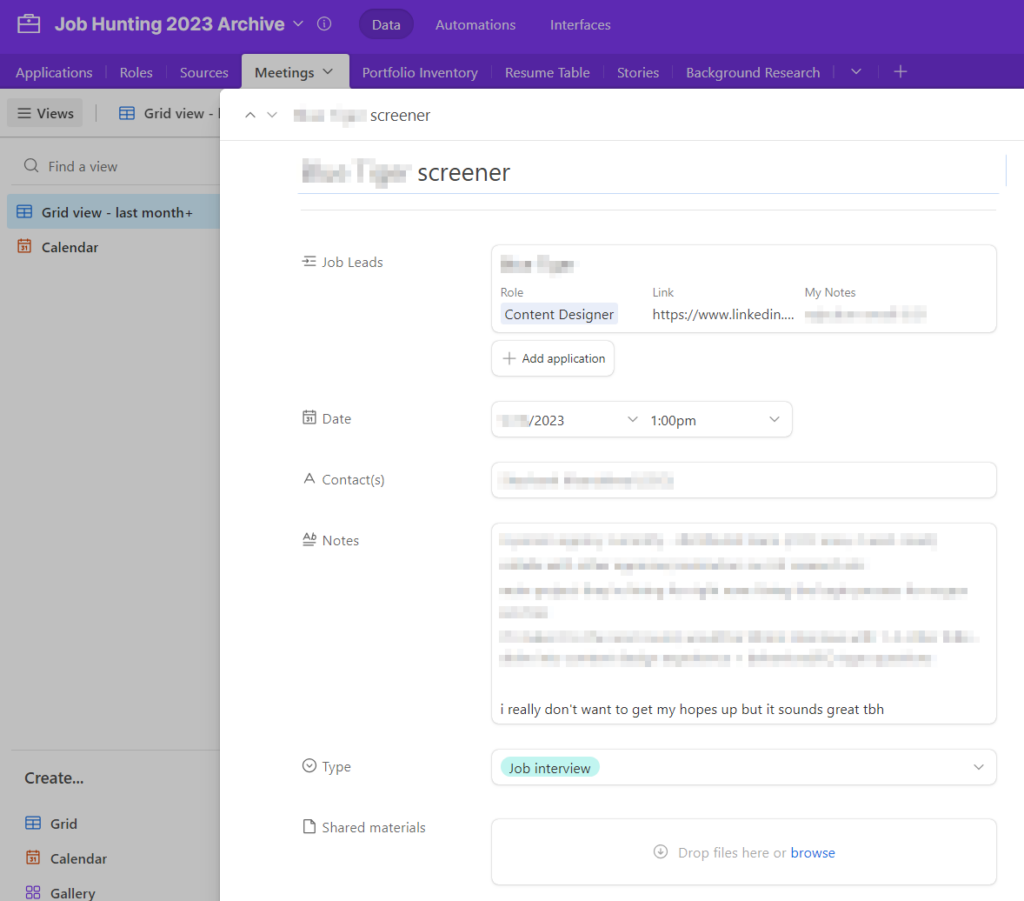
Goal: To review my current resume/LinkedIn for keyword/skill matching and rewrite/edit as needed to better match job ad language.
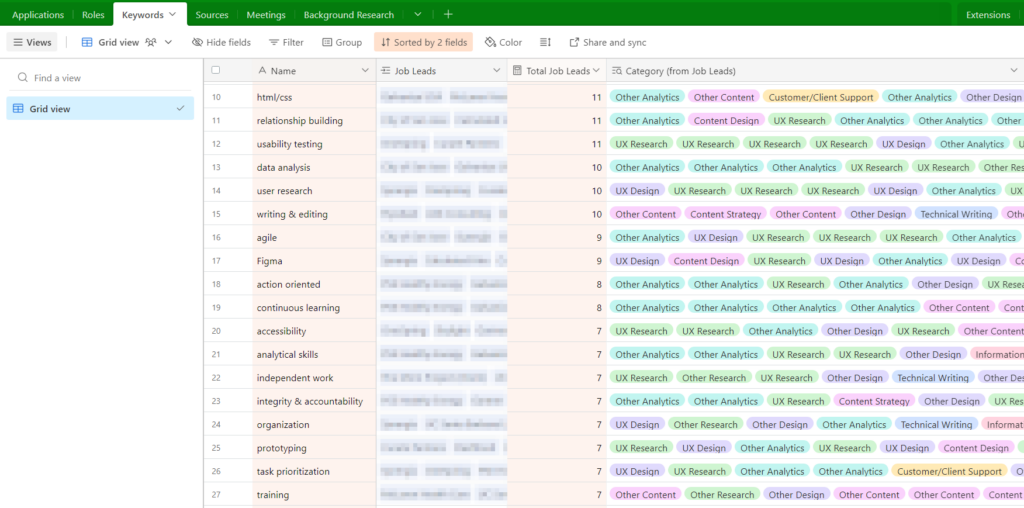
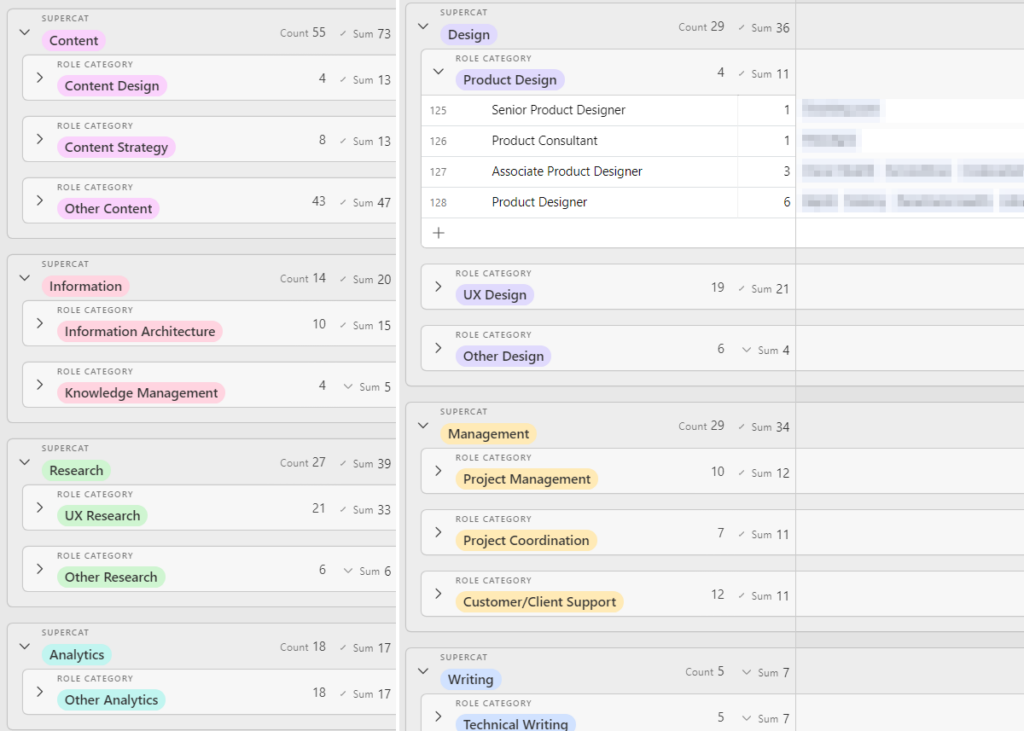
To prioritize a first pass, I went back to my google sheet that sorted keywords by the number of categories they were associated with and highlighted everything with 4+ categories. Then I went into my Airtable (keywords sorted by total jobs associated with them) and copied everything with 4+ jobs, pasted it into the same column of the spreadsheet with the label “FREQ” in the next column, and created a conditional formatting rule to highlight duplicates. There are 36 keywords that overlap, though both lists are worth reviewing.
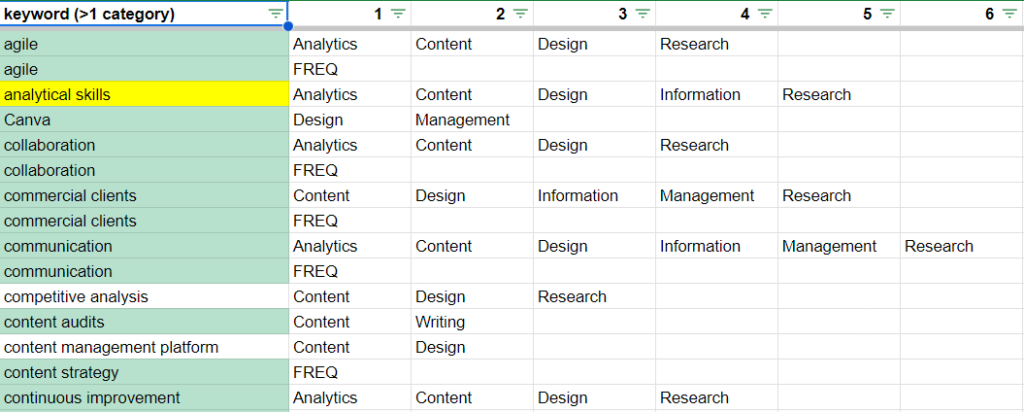
Did a quick pass of the resulting list to cross out skills/experiences I don’t have (commercial clients, cybersecurity) and italicize the weak/personal ones (accessibility, Figma). These are areas I’d love to get more training and experience in, but that’s not the point of this exercise.
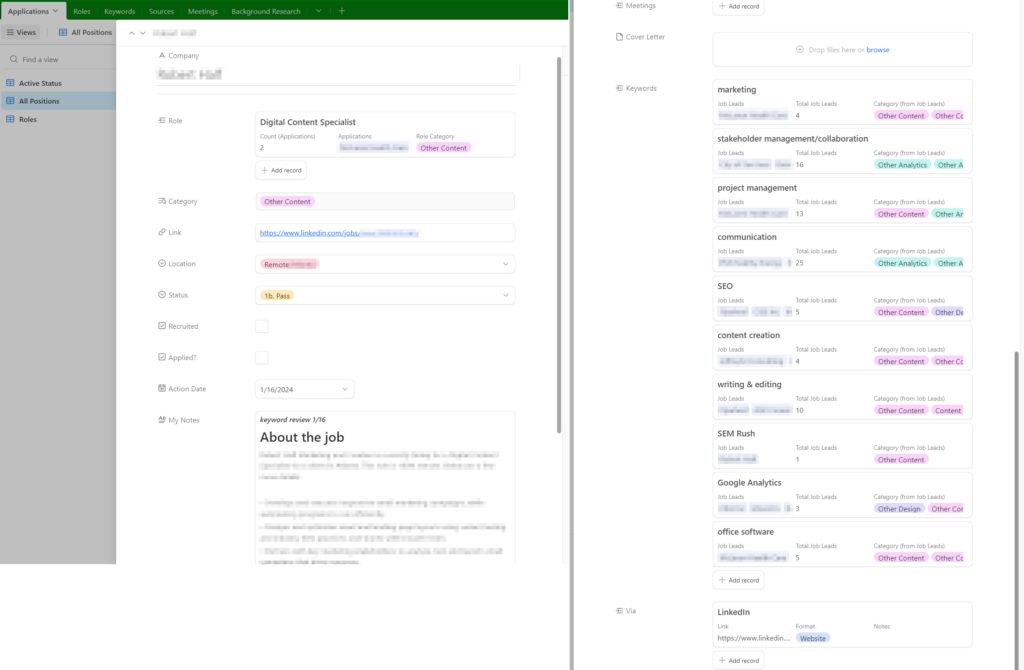
Working with a text-only copy of my existing resume, I went through the list and made a list of keywords I could readily associate with each job/educational experience.
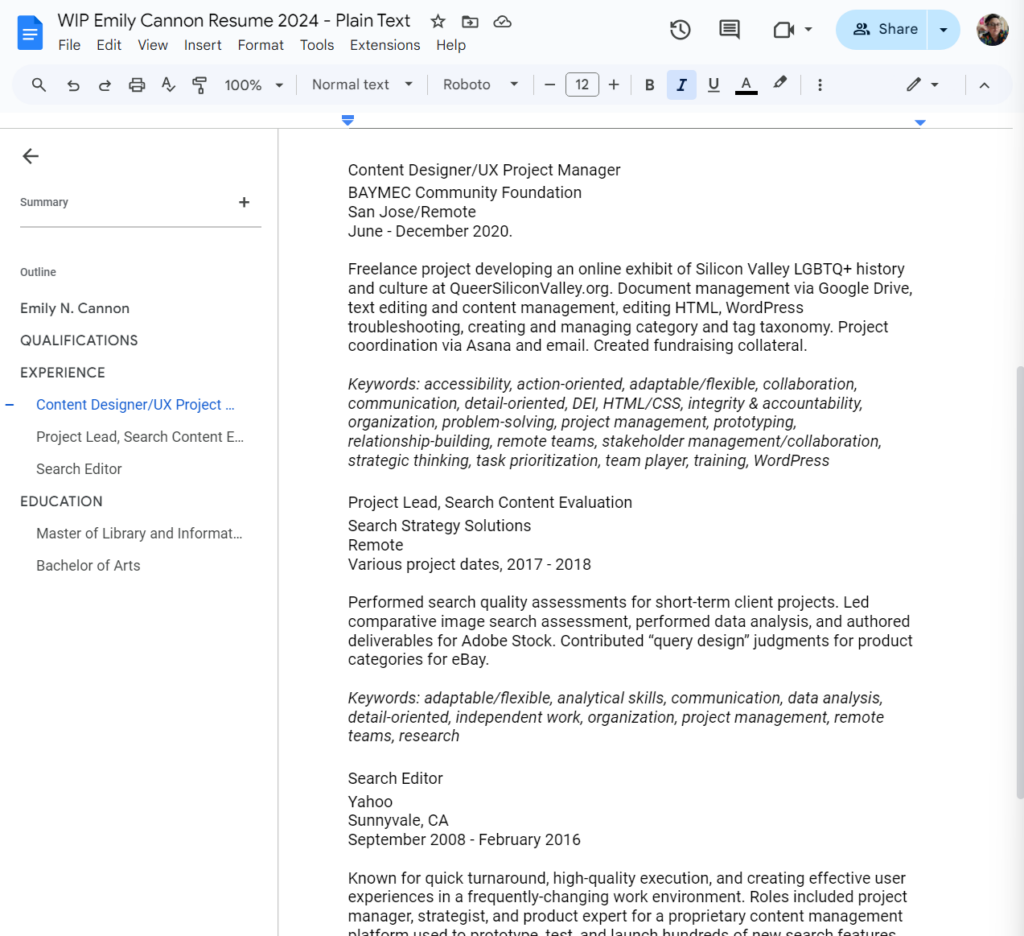
I also added keywords under my grad degree, because it’s some of my stronger recent experience and covers a lot of skills not found elsewhere on my resume/portfolio. I highlighted a few terms that are worth calling out for that reason specifically.
There are a few roles I’ve historically left off the resume I send out due to space concerns and lack of relevance, but for the sake of completeness, I reviewed them for keyword relevance as well. At the very least, I can update them on LinkedIn.
For my first pass, I started with the shortest job descriptions and began drafting new descriptions, referring to the keyword list as much as possible. Once I was satisfied with the updated descriptions, I made a fresh formatted resume, taking into account a few things I’d read about applicant tracking system-friendly design and keeping it very simple and consistent. I even left off my cute little logo. Although it’s my goal with this process to create a modular resume that can be longer than one page if necessary, the first revision is meant to replace my basic one-page resume.
Once I felt good about my new one-pager, I tested it with one of those sites that scans resume text and compares it to a given job description, offering feedback on keywords and text parsing. My experience with that site was that it really wanted to sell me something, and hey, I’m unemployed, I’m scrounging my pennies, gimme a break, but thank you for the feedback that wasn’t behind a paywall, anyway. I made a few tweaks and downloaded my one-pager as a PDF, ready to submit to the next opportunity.
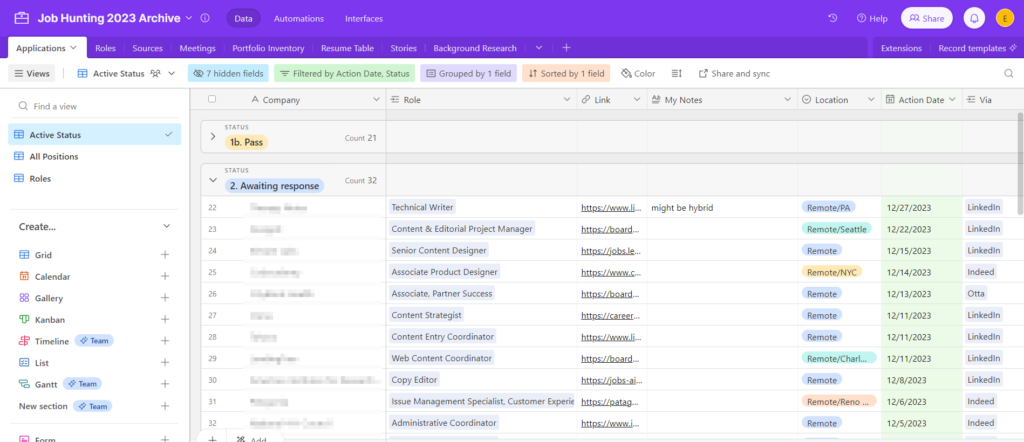
I also updated LinkedIn with these edits and added the update as a “Meeting” in my application tracker Airtable, just for my own records. Additionally, I did a quick pass cleaning up the tags associated with my portfolio site, since they’re displayed in a cloud for navigation, as well as adding these blog posts at the bottom of the portfolio page (oh hey!).
For my next trick, I’ll be going category by category, with a similar process as the starting point, albeit with different filters on frequency. I may also attempt to roll up some of the “tail” keywords (those associated with one role in my sample) for patterns that can contain multiple keywords or easily be edited to match a job description’s language.