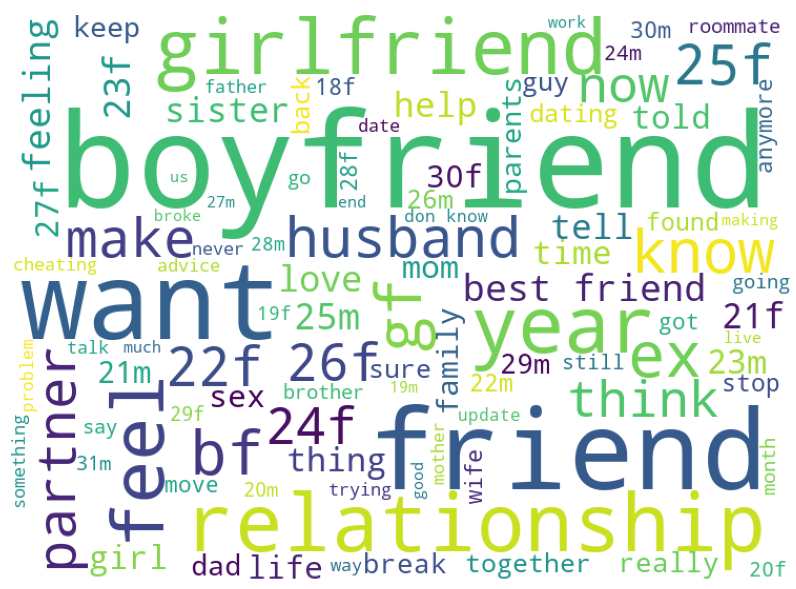
Based on a student data project that used Python machine learning libraries to analyze text from the social news and discussion site Reddit, we developed a scholarly research paper to submit to the HICSS 2022 conference. Focused on two popular advice subreddits, we created manual coding data to identify user demographics disclosures, described whether any patterns could be observed when comparing user metrics and algorithmic scores, and speculated on the role community moderation played in interpreting study data. I was first author on the published paper, co-author of the original student project, performed much of the data labeling and quantitative analysis, and presented our findings at the virtual conference. I offered guidance and feedback for other authors.
Because basic statistical analysis failed to suggest any interesting patterns with metrics or text analysis algorithms, we chose to frame the study as an exploration of behavior and identity disclosure in semi-anonymous environments. To that end, we needed to expand our original attempt to automatically extract demographics based on text pattern matching logic and instead manually reviewed each post to identify age and gender, if explicitly included. This allowed us to draw inferences between our forums of interest in terms of disclosure rates and community moderation and expectations. Furthermore, we could comment on extraction methods in general, suggesting principles to avoid assumptions and maximize accurate coverage of demographic information that future researchers could use.
In addition to scalability issues with demographics disclosure, we realized that we should have more carefully considered which subreddits to include in our dataset–ideally those with similar community guidelines–which may have resulted in more compelling analysis using the same algorithms and metrics data we originally collected. This may have allowed us to go beyond an exploration of demographics and disclosure. This was a scholarly work, so its effect, if any, may not be seen for some time.
- “Don’t Downvote A$$$$holes”: An Exploration of Reddit’s Advice Communities in the Proceedings of HICSS
- Presentation slides and notes on Google Drive
Because of this project, we learned some of the limitations and opportunities for using Python to explore online communities. Personally, it was an excellent opportunity to participate in the scholarly publication process and prepare a presentation of the project.